Boost with api for microservices: Scalable APIs for mobile apps

APIs are the glue that holds a microservices architecture together. Think of them as the official contracts that define exactly how your independent services talk to each other.
When a user taps "view profile" in your mobile app, an API call zips over to the dedicated user service. When they hit "buy now," a completely separate API call shoots over to the payment service. This clean separation is what lets each component scale and evolve on its own.
Why APIs Are the Heart of Microservices
Imagine your application is a bustling restaurant kitchen. Each microservice is a specialist chef—one for grilling, one for sauces, one for desserts.
In this world, your APIs are the waiters. They don't cook the food themselves, but without them, the whole operation would collapse into chaos.
When a customer (your app user) places an order, the waiter (the API) takes that request and translates it into precise, standardized instructions for each chef. The grill chef gets the steak order, the sauce chef knows which side is needed, and the pastry chef preps the final course. This communication is clear and reliable. Without these "waiter" APIs, you'd have chefs guessing at orders and customers getting the wrong food.
Enabling Independent and Rapid Development
The real magic of using an API for microservices is the freedom it gives your development teams. Because each service communicates through a well-defined API contract, teams can work on their own turf without breaking anyone else's code.
For a deeper dive into how this plays out in the real world, especially with container orchestration, check out this guide on scalable microservices systems with Kubernetes.
This separation has huge business implications:
- Faster Deployments: The payments team can push a critical security update multiple times a day without forcing the user profile team to redeploy a thing.
- Reduced Risk: If a bug creeps into the recommendations service, it won't take down user authentication. The failure is contained, protecting the core experience.
- Technology Freedom: One team can build a service in Python while another uses Java. As long as both honor their API contracts, it just works. This lets you pick the best tool for the job, every time.
An API-driven approach flips the switch on a monolithic development process, turning it into a parallel one. Instead of one massive, risky release cycle, you have dozens of smaller, faster, and safer releases happening all the time. This radically improves your ability to innovate and react to the market.
Fueling a Growing Digital Economy
This architectural shift isn't just a technical detail; it's the engine powering modern software. The global open API market, which is the foundation of this model, is seeing explosive growth.
The market is projected to rocket from $4.53 billion in 2026 to an incredible $31.03 billion by 2033. That’s driven by a massive 23.83% compound annual growth rate. This incredible expansion shows just how vital APIs have become for building the software that runs our world.
Choosing the Right API Communication Style
Picking the right API style for your microservices is a bit like a chef choosing the right knife. A butcher knife, a paring knife, and a bread knife all cut, but you wouldn't use one for another's job. Using the wrong tool makes the work harder, messier, and slower. The same goes for APIs: REST, gRPC, and GraphQL are all designed to let services talk, but picking the right one from the start is critical.
Get this decision right, and your services will be efficient, your public APIs will be a joy for others to use, and your mobile apps will feel snappy. Get it wrong, and you're looking at painful rewrites and performance headaches down the road.
This decision tree can help you visualize how these choices flow from your core architecture.
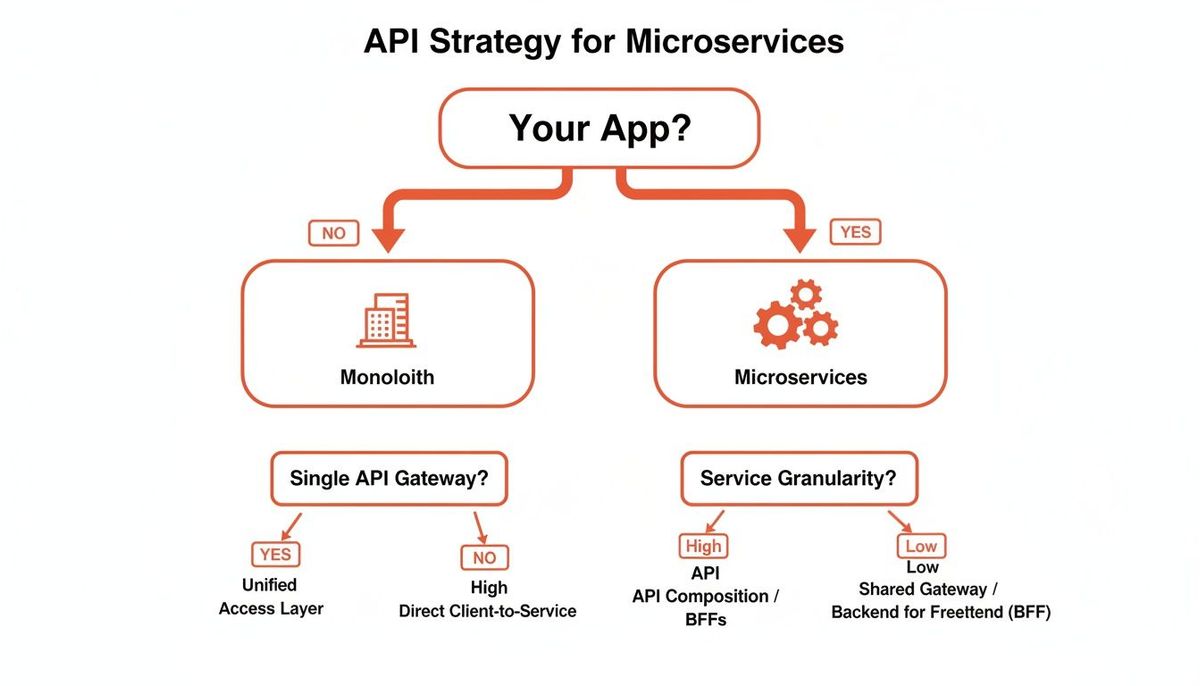
As the chart shows, once you commit to microservices, the decisions around API gateways and how you slice up your services become front and center.
To help you make an informed decision, let's break down the big three and see where they shine.
Comparison of API Styles for Microservices
This table gives you a quick, side-by-side look at how REST, gRPC, and GraphQL stack up against each other based on what usually matters most when building a backend for mobile apps.
| Criterion | REST (Representational State Transfer) | gRPC (gRPC Remote Procedure Call) | GraphQL (Graph Query Language) |
|---|---|---|---|
| **Primary Use Case** | Public APIs, simple service-to-service communication. The web's universal language. | High-performance internal, service-to-service communication. The backend speedster. | Mobile/frontend clients, Backend-for-Frontend (BFF). The flexible data fetcher. |
| **Data Format** | JSON (human-readable text) | Protocol Buffers (binary format) | JSON (human-readable text) |
| **Performance** | Good, but can be verbose. Slower than binary formats. | Excellent. Low latency due to binary format and HTTP/2. | Very good for clients. Reduces network calls, but server overhead can be higher. |
| **Ease of Use** | Very easy. Widely understood and supported by virtually all tools and languages. | Moderate. Requires `.proto` files and specific tooling to generate code. | Moderate to difficult. Steeper learning curve for backend implementation. |
| **Flexibility for Clients** | Low. Fixed data structures mean clients get what the endpoint provides (over/under-fetching). | Low. Rigid service contracts defined in `.proto` files. Not client-driven. | High. Clients request exactly the data they need, no more, no less. |
| **Tooling & Ecosystem** | Massive. Every language and framework has first-class support. | Growing rapidly, strong support from Google and the CNCF. | Strong and growing, especially in the JavaScript/frontend community. |
Each style has its place. REST is your reliable default for public APIs, gRPC is your internal engine for high-speed chatter, and GraphQL is your specialist for giving frontend clients precisely what they need.
REST: The Universal Translator
If APIs had a universal language, it would be REST. Built on the same HTTP principles that power the web (think GET, POST, PUT), it's the style every developer on the planet understands. Its simplicity and massive ecosystem make it the default choice for public-facing APIs where you need maximum compatibility with the outside world.
REST is also the undisputed king of internal service-to-service communication. A staggering 78% of organizations use REST APIs to connect their microservices. It's not just a trend; it's the bedrock of modern systems, with 92% of Fortune 1000 companies running REST APIs in production.
Here’s a practical example of a clean, stateless REST request to fetch a user profile.
GET /users/123 HTTP/1.1
Host: api.yourapp.com
Accept: application/jsonBecause each request is self-contained and uses standard HTTP verbs, RESTful services are easier to scale and debug, making them a solid foundation for your architecture.
gRPC: The High-Speed Specialist
Built by Google, gRPC is all about one thing: speed. It's the specialized tool you pull out for blazing-fast communication between your internal microservices. Where REST uses human-readable JSON, gRPC uses Protocol Buffers—a compact binary format that’s much faster for machines to process.
Think of it as your services talking to each other in a private, highly optimized shorthand instead of a formal, public language. That efficiency is a game-changer for high-throughput systems. For instance, a logging service that ingests thousands of events per second would benefit massively from gRPC's low latency.
gRPC gets its performance edge from using HTTP/2, which enables advanced features like sending multiple requests over a single connection (multiplexing) and bidirectional streaming. This makes it the clear winner for the complex, low-latency chatter happening behind the scenes.
A gRPC call is defined by a strict contract in a .proto file, which leaves no room for ambiguity:
// The user service definition.
service UserProfile {
// Sends a request for a user profile
rpc GetUserProfile (UserProfileRequest) returns (UserProfileReply) {}
}
// The request message containing the user's ID.
message UserProfileRequest {
string user_id = 1;
}
// The response message containing user details.
message UserProfileReply {
string username = 1;
string email = 2;
}This is perfect for the high-volume traffic inside your backend, but less so for public APIs where simplicity and broad compatibility are key.
GraphQL: The Flexible Data Maestro
Created by Facebook to solve their mobile app woes, GraphQL is the ultimate flexible data maestro. The problem with traditional REST APIs is that they often lead to over-fetching (getting way more data than you need) or under-fetching (having to make multiple API calls to piece together the data you want). This is a killer for mobile app performance.
GraphQL flips the script. It empowers the client—your mobile app or web frontend—to ask for exactly what it needs in a single, precise request. This power to shape the data response is invaluable, as you can see in our guide on using Bubble.io as a mobile backend.
A GraphQL query is beautifully explicit. Here, the client asks for just two specific fields for a user:
query {
user(id: "123") {
username
email
}
}This precision is why GraphQL has become the go-to choice for building a Backend-for-Frontend (BFF). It acts as an efficient middleman that serves tailored data to your mobile and web clients, making them faster and more efficient. An effective api for microservices needs this kind of client-centric flexibility.
Managing Complexity with an API Gateway
As your app grows, you'll hit a point where you go from a handful of microservices to dozens. Suddenly, a new problem sneaks up on you. Your mobile app is now forced to talk directly to every single service—user profiles, product catalogs, payments, reviews—creating a tangled mess of network calls. This is bad news.
This direct communication makes your client app complex, brittle, and slow. It's suddenly become a traffic controller, a job it was never built for.
This is exactly where the API Gateway pattern saves the day. Think of it as the single, organized front door to your entire system. Instead of clients knocking on ten different doors to get what they need, they make one call to the gateway. The gateway then intelligently routes those requests to the right internal services, gathers up the responses, and sends back one unified payload.

This approach dramatically simplifies life for your frontend team. They no longer need to know the addresses of ten different services or write complicated logic to stitch data together. They just talk to one reliable endpoint. It’s that simple.
Centralizing Cross-Cutting Concerns
One of the biggest wins you get from an API Gateway is its ability to handle tasks that apply to all services. We call these cross-cutting concerns. By centralizing these jobs, you keep your individual microservices lean, focused, and free from repetitive boilerplate code.
Here are the key responsibilities you can offload to an API Gateway:
- Authentication and Authorization: The gateway can check a user's identity (say, by validating a JWT) long before a request ever hits a microservice. This means your
product-servicedoesn't need any auth logic at all; it can simply trust that any request it receives is already authenticated. - Rate Limiting: To stop bad actors or prevent system overloads, the gateway can enforce rules like "a user can only make 100 requests per minute." This protects all your downstream services without them needing to implement their own rate-limiting code.
- Request Routing: The gateway acts as a smart reverse proxy. It maps a public-facing URL like
/api/v1/userto an internal service address likeuser-service:8080/profile. - Logging and Monitoring: It becomes the perfect choke point to log all incoming traffic. This gives you a complete, high-level view of system usage and performance in one place.
By handling these tasks centrally, the API Gateway streamlines your entire api for microservices architecture, making it far more secure and manageable.
The Backend-for-Frontend (BFF) Pattern
A general-purpose API Gateway is a huge step up, but you can take this idea even further with the Backend-for-Frontend (BFF) pattern. A BFF is just a specialized API Gateway built to serve the exact needs of a single client application—like your iOS app, your Android app, or your web dashboard.
The core idea behind the BFF pattern is simple: instead of a one-size-fits-all API, you create a tailored, optimized API for each specific frontend experience. This moves the messy work of data aggregation and transformation off the client and onto the server, right where it belongs.
Let's make this real. Imagine your mobile app's main dashboard needs to show the user's name (from user-service), their five most recent orders (from order-service), and a personalized product recommendation (from recommendation-service).
Without a BFF, the mobile app has to make three separate network requests, wait for all of them to finish, and then stitch the data together on the device. This is slow, drains the battery, and is a nightmare on a spotty network connection.
With a BFF, the mobile app makes a single call to an endpoint like GET /mobile/dashboard. The BFF then makes the three internal calls in parallel, combines the results into one perfectly shaped JSON object designed specifically for that dashboard view, and sends it back. The result is a faster, more responsive user experience and a much cleaner frontend codebase. This focused approach is a cornerstone of any high-performance api for microservices strategy.
Designing APIs That Evolve Gracefully
In a microservices world, change is the only constant. Your user service needs a new field, the payment service has to support a new processor, and your recommendations engine is getting a complete overhaul. So, the real question isn't if things will change, but how you update a service without breaking all the other services and mobile apps that depend on it.
This is where you have to design your API for microservices with evolution in mind from day one. Without a strategy, a simple update can cascade into a system-wide failure, forcing all your users to update their apps just to keep things working. That creates a brittle system and, frankly, a terrible user experience.
Graceful evolution means making sure older clients—like a user on a three-month-old version of your mobile app—can keep functioning perfectly even after you’ve deployed new backend features. You get there with a mix of smart versioning and a serious commitment to backward compatibility.
Choosing Your Versioning Strategy
When you absolutely must introduce a breaking change, you need a way for clients to tell you which version of the API they're built for. This is what stops a sudden update from crashing older applications. There are two primary, battle-tested ways to handle this.
- URI Versioning: This is the most straightforward approach. You just stick the version number right in the URL path, like
/api/v2/users/123. It's explicit, easy to spot in logs, and dead simple for developers to test in a browser. - Header Versioning: This method tucks the version info into a custom HTTP header, like
Accept-version: v2. The URL stays clean (/api/users/123), which some developers prefer because it keeps the URI focused purely on the resource itself.
While both are perfectly valid, URI versioning is often the winner for its clarity and ease of use. But the real strategy is to avoid needing explicit versions in the first place by defaulting to backward compatibility.
The ultimate goal isn't to have a perfect versioning system. It's to need it as infrequently as possible. True API resilience comes from making non-breaking changes the default for 95% of your updates.
The Art of Non-Breaking Changes
Instead of thinking in versions, start thinking in additions. The key to evolving gracefully is designing your APIs so new features can be added without ripping up the old contracts. This is all about embracing additive changes.
For example, say you need to add a user's preferred language to their profile. Don't create a v2 of your user object. Just add a new, optional field called preferred_language.
Older clients that have no idea this new field exists will simply ignore it. New clients can start using it immediately. The existing contract is honored, and nothing breaks. This simple principle is the bedrock of a resilient microservices architecture. Maintaining this stability is also vital for your backend processes; you can dive deeper into this with our guide on data syncing capabilities for business apps to see how it all connects.
A Checklist for Every Deployment
Before you ship any change to an API, run it through this quick mental checklist. It will save you a world of hurt.
- Are we adding only new, optional fields to responses? (Safe)
- Are we adding only new, optional parameters to requests? (Safe)
- Are we changing the data type of an existing field? (Breaking Change! Stop.)
- Are we removing a field from a response? (Breaking Change! Stop.)
- Are we making an optional request field mandatory? (Breaking Change! Stop.)
By making these simple rules part of your team's muscle memory, you can evolve your api for microservices quickly and safely. You'll deliver new value to users without ever disrupting their experience.
Securing Your Distributed Microservices APIs
When you break a monolith into a fleet of distributed services, your security perimeter vanishes. Gone is the single fortress wall. In its place, you have dozens of smaller, interconnected outposts, and each one needs to know who it can trust. This is why security can't be an afterthought; it has to be baked into the design of your api for microservices from day one.
The old way of doing things—passing a user's password from service to service—is a massive liability in this new world. If just one of those services gets compromised, an attacker suddenly has the keys to the kingdom. We need a much smarter, more decentralized way to handle trust.
This is exactly where token-based authentication comes in. Instead of shipping sensitive passwords around, we deal in temporary, verifiable credentials. It’s a simple shift that dramatically shrinks your attack surface and cleans up the security logic inside every single microservice.
The Role of a Central Authentication Service
The modern answer is to pull authentication out into a single, dedicated service. Think of it as your system's official passport office. This Auth Service is the only component that should ever see a user's password.
Its job is simple but absolutely critical. A user presents their credentials just once. If they check out, the Auth Service issues a digitally signed token. This token becomes a temporary passport, proving the user's identity to any other service without ever exposing the password again.
This setup gives you a few major wins:
- Password Isolation: User passwords are kept in one—and only one—hardened location. Your product and order services? They never even lay eyes on them.
- Simplified Logic: Your other microservices are freed from the messy business of hashing passwords or managing sessions. Their only job is to check the validity of the tokens they receive.
- Consistent Security: All your authentication rules and policies live in one place, making it far easier to enforce standards, roll out updates, and patch vulnerabilities.
Understanding the OAuth 2.0 and JWT Flow
The industry-standard, battle-tested pattern for this is OAuth 2.0 working alongside JSON Web Tokens (JWTs). A JWT is just a compact, self-contained token that carries information (called "claims") about the user, like their ID and permissions. The magic is that it's digitally signed, so any service can instantly verify its authenticity without having to call back home to the Auth Service.
Let’s walk through how this flow works in the real world:
- User Login: The user punches their username and password into your mobile app. That info is sent securely, and only to your central Auth Service.
- Token Issuance: The Auth Service validates the credentials. If everything looks good, it generates a signed JWT containing the user's ID and maybe their role (e.g.,
{"user_id": "123", "role": "customer"}). This token is sent back to the mobile app. - API Request with Token: The mobile app tucks this JWT away. Now, when it needs to fetch the user's order history, it makes a request to the API Gateway and includes the JWT in the
Authorizationheader, usually as a "Bearer" token. - Gateway Validation: The API Gateway is the bouncer at the front door. It intercepts the request, checks the JWT's digital signature to confirm it’s legit and hasn't been tampered with, and makes sure the token hasn't expired.
- Secure Downstream Call: Once validated, the API Gateway forwards the request to the
order-service, maybe adding a header with the now-verified user ID. Theorder-servicecan trust this request is authentic and get straight to business. For an even more robust login, you can easily implementing two-factor authentication at the first step.
By offloading token validation to the API Gateway, you achieve a powerful separation of concerns. Your individual microservices are freed from the burden of security checks and can focus purely on their core business logic. They simply trust that any request coming from the gateway is already authenticated.
This entire flow ensures that the api for microservices is secured at the edge, creating a robust and scalable architecture. It means your developers can spin up new services without constantly having to reinvent the security wheel, which ultimately leads to shipping better features, faster.
Ensuring Your System Is Reliable and Observable
Deploying a web of interconnected services is one thing. Proving they all work together reliably is a completely different beast. How do you trust that your order-service and payment-service are still speaking the same language after five independent updates?
This is where testing and observability shift from "nice-to-haves" to absolute must-haves for any serious microservices architecture. It’s the only way to build confidence in a system that’s constantly changing.
Traditional end-to-end tests, where you simulate a full user journey, are notoriously slow, fragile, and a nightmare to maintain in a microservices world. A much better approach is to focus on the "contracts" between services, ensuring each party upholds its end of the API bargain.

This focus on reliability isn't just a technical detail; it's a massive business trend. The microservices market, valued at $2,073 million in 2018, is projected to rocket to $8,073 million by 2026, riding an impressive 18.6% annual growth wave. It’s a huge shift, and getting reliability right is non-negotiable.
Verifying Integrations with Contract Testing
Contract testing is a technique that verifies the interactions between services without having to spin them all up at once. Think of it like a legal contract: one service (the "consumer") lays out its expectations, and the other (the "provider") agrees to meet them.
The process is deceptively simple but incredibly powerful. The consumer service generates a "contract" file detailing the exact requests it will make and the responses it needs. The provider service then runs tests against this contract to prove it can deliver.
Actionable Insight: Use a tool like Pact. Your Order Service (the consumer) can define a contract stating, "When I ask for user details for ID 123, I expect a JSON response with an email field that is a string." The User Service (the provider) then runs this contract as part of its CI/CD pipeline. If a developer on the User Service team tries to rename email to email_address, the build will fail, preventing the breaking change from ever reaching production.
This approach catches integration bugs before they ever see the light of day. It’s a lightweight, fast-feedback alternative to clunky end-to-end tests, giving you high confidence that your services can actually talk to each other in production.
The Three Pillars of Observability
When a user reports that "the app is slow," how do you pinpoint the cause in a system of 50 different microservices? This is where observability comes in. It’s not just monitoring; it’s about having the ability to ask any question about your system's state just by looking at the data it produces.
True observability is built on three core pillars:
- Logs: These are the nitty-gritty, timestamped records of events. A log might say, "User 123 failed to update profile at 10:15:02 AM due to invalid email." They are perfect for deep-diving into specific errors.
- Metrics: Think of these as the high-level dashboard gauges for your system—aggregated, numerical data like "CPU usage is at 85%" or "API error rate is 2%." Metrics are what you use for monitoring and alerting.
- Distributed Tracing: This is the magic that ties everything together. Tracing follows a single request as it hops from one microservice to the next, giving you a complete visual map of its journey through your system.
Following a Request with Distributed Tracing
Imagine a request to place an order. It might first hit the API Gateway, then the order-service, which in turn calls the payment-service and the inventory-service. Without tracing, this is just a black box.
Distributed tracing assigns a unique ID to that initial request and passes it along at every single step.
This allows you to visualize the entire flow, seeing exactly how long each service took to do its part. You can immediately spot bottlenecks—like discovering the inventory-service took three full seconds to respond—and debug complex issues that would otherwise be impossible to track down.
Actionable Insight: Implement a tracing tool like Jaeger or OpenTelemetry. When a user's POST /orders request times out, you can pull up its trace. The trace might reveal that the API Gateway took 10ms, the order-service took 50ms, but the downstream call to the inventory-service took 4,940ms. You've instantly isolated the problem without having to dig through logs from three different services.
To really push your system and find these weak spots before your users do, it’s critical to understand the ins and outs of load testing microservices.
Burning Questions About Microservices APIs
Moving to a microservices architecture isn't just a technical shift; it's a new way of thinking. It's only natural that some tough questions come up along the way. Here are the straight answers to the most common challenges you'll hit when designing your api for microservices.
When Should I Stick With a Monolith?
Honestly? You should rethink microservices for small projects or early-stage startups with a lean team. The operational overhead is no joke. Managing deployment, monitoring, and all the complex chatter between services can absolutely crush you when speed is your biggest weapon.
A well-structured monolith is often a much smarter, faster starting point. You can always carve it up strategically later when your team and the product's complexity actually demand it.
How Do You Keep Data Consistent Across Services?
This is a big one. Unlike a monolith with its single, ACID-compliant database, microservices have to work a bit harder to keep data in sync across different services and their dedicated databases.
A powerful and widely-used solution is the Saga pattern. Think of it as a carefully choreographed sequence of local transactions that span multiple services. If any single step in that dance fails, the saga triggers "compensating transactions" that gracefully undo everything that came before it.
For example, booking a trip involves aBooking Service, aPayment Service, and aNotification Service. If the payment fails halfway through, a compensating transaction automatically cancels the booking. This gets the system back to a consistent state without a single, massive, blocking transaction.
It’s how you maintain data integrity without grinding your entire system to a halt.
What's the Single Biggest Hurdle in a Microservices Migration?
It's almost never the technology. The biggest challenge is almost always cultural and organizational. You're fundamentally changing how people work—moving from one large team on a single codebase to multiple, autonomous teams that own their services from end to end.
This requires a complete overhaul of your processes for communication, deployment coordination, and who is ultimately responsible for what. If you don't tackle this cultural shift head-on with clear service boundaries and rock-solid communication channels, it will become the biggest roadblock to your success.
Ready to build a mobile app that scales and drives revenue? The team at Vermillion partners with funded startups to deliver revenue-ready React Native products with a performance-based model tied to your business KPIs. Learn more about our approach.